O h how English is always at the end of our ire. A brave language it is, really, with its now dead ‘k’s in knights and combs, bombs, tombs, and inconsistent rules and exceptions that make no sense.
English is the language everyone loves to hate, perhaps not without reason. Say the following sentence out loud:
Learning English is rough, but it can be understood through tough thorough thought though.
Or, if you’re feeling rather ambitious, try reading this poem written by Dutch writer Dr. Gerard Nolst Trenité in the 1920s, entitled quite aptly “The Chaos”.
Chances are, even if you’re familiar with the language, you agree that limiting tongue gymnastics when speaking is an excellent idea. To be fair, many of these irregularities arise from the fact that English, as spoken today, is a kaleidoscope of French and Latin words, and even Greek and Old Norse thrown in for good measure. Trying to manage words derived from different languages and fit them into our sound and grammar patterns was (and is) alone is a hefty job, so spelling is regretfully left to the wayside.
The problem here is a high ratio of sounds to letters and letter combinations — ‘ough’ alone produces ten different pronunciations, give or take a few depending on the specific accent or dialect. While there are patterns in spelling, English lacks one-to-one correspondence, meaning one letter does not correspond to one and only one sound. In other words, the alphabet has 26 letters, but there are 44 distinct sounds in spoken language, of which 19 are vowels! The lexicon does make use of digraphs (two letters to represent one sound), like ‘ai’ in ‘fail’ or ‘ei’ in ‘heist’, in an attempt to specify sounds that don’t have individual symbols. Other rules like “Silent E makes the vowel say its name”, turning ‘spit’ to ‘spite’, or the letter ‘c’ almost always being pronounced as a soft c (‘s’ sound) when preceding an ‘i’ or ‘e’ like ‘citrus’ or ‘cent’, can give us clues to guide us to the correct pronunciation. Yet these contextual clues don’t always hold true, and due to different origins of different words, may not contain them at all.
The Latin script thatEnglish uses, with a dash of Greek, Latin, and French spelling, is simply not efficient as it could be. Rapidly changing phonemes and phonology yet relatively unaltered spelling has also contributed to an ever-increasing chasm between sounds and writing. English is also the only modern European language that doesn’t make much use of diacritics (with few exceptions in certain loanwords, often omitted), a useful feature that could put into writing the different ways the two ‘e’s are pronounced in ‘eroded’, for example.
Why the exposé on the root of our mispronunciation mishaps? Because it sets the stage for 한글 (transliteration: Hangul, translation: Korean), what I believe to be perhaps one of the most intuitive and easiest scripts to exist, and to encourage others to learn a rather unconventional (uncommon, linguistically speaking) alternative to the orthographies most of us familiar with.
Bit of History
Most alphabets you see today are alphabetical scripts based on the North Semitic writing system in the Levant circa 2 BCE. It gave way to Aramaic and Phoenician alphabets, which gave way to Indian, European, and Semitic alphabets. The story of Hangul begins with classical Chinese. But however tempting it is to group Korean with major East and South East Asian languages like Mandarin or Japanese, they actually are not related with the definitiveness of languages like Arabic and Hebrew, or French and Spanish. Some linguists have proposed theories about proto-language families grouping them, but currently Korean and varieties of Chinese are considered language isolates (not belonging to any known language family).
During the Proto-Three Kingdoms era in 1st century BC in the Korean Peninsula, classical Chinese characters were brought and adapted to the Korean language. These are known as Hanja, and are still used in Korea today, though minimally and usually in literary texts. Some road signs even include both individually, or as a mixed script, using both Hangul and Hanja in one phrase/sentence (couldn’t find a public domain photo, but google “Korean road signs hanja”).

This is an example of a mixed script. These are the lyrics to the Korean National Anthem, adopted for just short of a decade in the early 20th century.
Even without any knowledge of the language, a keen eye can differentiate between two types of “blocks” here. It might be easiest to categorize them complicated vs simple blocks, but more specifically, some of the characters have many and multi-layer strokes — these are Hanja — versus those with fewer, straighter lines — Hangul. But I call the latter blocks, not characters, because as we’ll soon see, each of those lines are a letter or part of one. Each of the Hanja characters is also followed by Hangul in tiny writing, though they only present here to clarify pronunciation, and would not normally be written.
Though the writing system used mostly Hanja for over a millennium, it was reserved for the elite and usually only understood by this subsect of society. Each Hanja character is unique and you have to memorize hundreds, if not thousands, of characters individually to be able to string together sentences. To that end, Joseon King Sejong created Hangul, writing the preface to a document in 1446 titled Hunminjeong’eum (The Proper Sounds for the Education of the People) and tasking scholars to describe the new alphabet. It was quickly picked up by the public, though not without a fight by the elites.
So in short, yes — Hangul is distinct in that it was designed purposefully to be easy and phonologically consistent with speech.
The Script
The modern form consists of 21 vowels and 19 consonants. It might sound daunting to the English speaker, but think about our own system mentioned above. What’s easier, learning 26 letters and being left to float in a sea of other grammar and context clues to help pronounce words, or memorizing a set of 40 letters that give you all the sounds needed for the language?

Hangul is the more phonologically faithful than many writing systems. Meaning, almost each symbol corresponds to one sound with little exception. Written left to right, the system at first glance may look like Chinese characters, but it couldn’t be more different. Our problem is looking at them in solely in blocks — which they are — and neglecting the pieces that make up a whole.
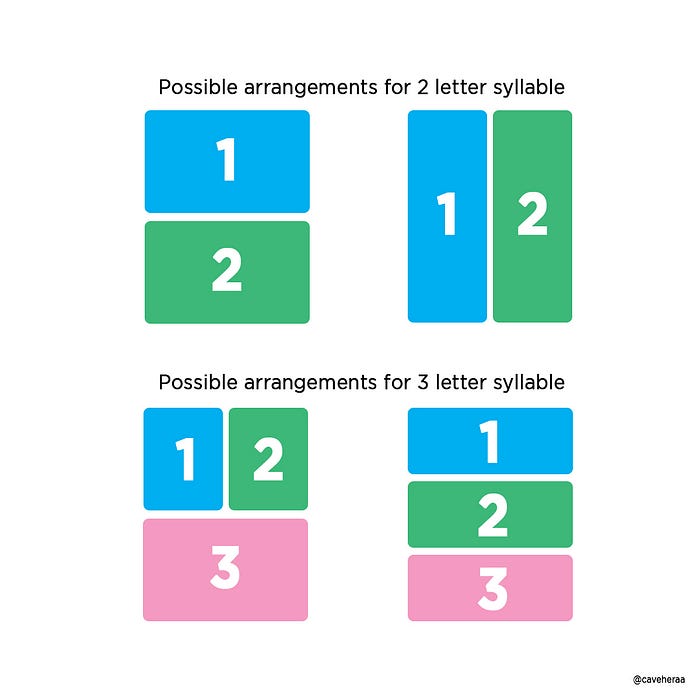
We’re used to English, where each letter is one space on a horizontal line, rather than segments that can move up and down. This is because in Hangul, each block is one syllable, consisting of 2–3 letters (sometimes 4, we’ll get to that later). It makes it easier for pronunciation as well, as each syllable is clearly defined in these blocks.
Let’s use the word 한글 (Hangul) as an example. There’s two syllables, ‘han’ and ‘gul’.
The first syllable, or block, is 한 (han). It has three sounds, and, in accordance with the lovely one sound-to-one letter feature, means three letters.
Now that we know how many letters in the syllable, we have to arrange them in the appropriate pattern in a block. When a block has three letters, there’s two options: put the first and second letters next to each other, and the third below, or all three stacked on top of each other like a pancake.
How do we know which arrangement to use? By looking at the vowel. Syllables are consonant-vowel (CV) if 2 letters or consonant-vowel-consonant (CVC) if 3 letters. Position 2 must always be occupied by a vowel. If the vowel is vertical looking, go with the option that places it next to the first letter. If the vowel is horizontal, pancake it.
First letter is ㅎ ‘h’.
Second letter isㅏ ‘a’, a vertical looking vowel.
Third letter is ㄴ ‘n’.
Then arrange into a block, so instead of ㅎㅏㄴ, with the letters spaced across a horizontal line like you would in English, it’s 한, in one block.
Does every syllable follow this pattern? Yes. Must every block be CV or CVC? Yes. There is a ㅇ letter that signifies a null sound (no sound) when placed in the left position in the block, so that gives room for words/syllables to start with vowels. There are also some double consonants (CC) and double vowels (VV), but they only appear in pairs, so we can count them as one consonant/vowel and put them in the appropriate position.
Also, all the vowels are easy to pick out, as they consist only of straight vertical and/or horizontal lines. There are other consistent patterns, like:
- Adding a double short line adds a ‘y’ sound to the vowel (ㅏ ‘a’ becoming ㅑ ‘ya’).
- Doubling a consonant to make it a ‘harder’ consonant— (ㄱ ‘g’ to ㄲ ‘k’). This is an example of a double consonant, but appear in a pair and for ease can be counted as one letter when arranging them in a block.
A final point of appreciation is how some of the vowels are designed to look like the shape of the mouth when pronouncing them, ㅜ is ‘u’, ㅡ is ‘eu’, a sound that can only be pronounced when the lips are stretched wide.
So, if you ever have a free few hours, learn 한글 for the heck of it. Or seriously. Of course, this doesn’t mean the language overall (reading, writing, speaking) is easy or hard to learn. One reply rightly points out that when learning Korean especially as a native English-speaker, it takes time to develop the ear to demarcate distinctive sounds. Some Korean vowel sounds don’t even exist in English. However, none of this should stop you from trying, and I truly believe that the writing system is a joy to learn.
The point isn’t to add another cool party trick to your repertoire — nor should such a lovely language be reduced to such — but to see that language learning isn’t mechanical memorization. It’s history so deftly spun that we only see the lines that hide a trove of ancient gems.
